TÜRKÇE METİNLERDE SES OLAYLARININ BULUNMASI, CÜMLE SONU BELİRLEME, METİN VE KELİME ANALİZİ
2014 yılında TUBİTAK Ortaöğretim Öğrencileri Arası Araştırma Projeleri Yarışması için öğrencilerimizle birlikta hazırladığımız ve Bölege 2. si derecesi elde ettiğimiz Yazılım alanındaki projemizi sizlerle paylaşıyoruz.
Doğal dil işleme ile Türkçe metinlerin morfolojik olarak incelenmesi ve bazı Türkçe ses olayların bulunmasını konu alan projemiz için hazırladığımız raporun tamamına buradan erişebilirsiniz.
Sitemizde yine TUBİTAK Ortaöğretim Öğrencileri Arası Araştırma Projeleri Yarışması için hazırlanmış farklı alanlarda katılım göstermiş, bölge sergisine davet edilmiş, ödül almış bir çok proje örneği bulabilrsiniz.
PROJENİN ALANI : BİLGİSAYAR
PROJENİN ADI : TÜRKÇE METİNLERDE SES OLAYLARININ BULUNMASI, CÜMLE SONU BELİRLEME, METİN VE KELİME ANALİZİ
İçerik Tablosu
ÖZET
Eğitimin her kademesinde Türkçe dersinde bazı dil bilgisi konularının öğrenciler tarafından anlaşılması ve konu ile ilgili soru çözülmesinde zorlanıldığı görülmektedir. Projemiz öğrencilerin dil bilgisi derslerinde zorlandığını düşündüğümüz ses olaylarının bilgisayar yardımıyla metin içerisinde gösterilmesini sağlamakta bu sayede öğrencilerin konuyu daha iyi kavramalarına olanak sağlamaktadır. Aynı zamanda öğretmenlerin de Ses olayları konusunda yeni örnekler üretebilmelerini sağlamaktadır. Programımız Türkçe metinlerde öğrencilerin karşılaştığı ses olaylarının bulunup işaretlenerek öğrencilere yardımcı olmaktadır. Türkçe Dilbilgisi eğitiminde öğretilen temel ses olaylarının (Ulama, Ünlü Sertleşmesi, Ünlü Daralması) metin içerisindeki gösterimini kolaylaştırmayı amaçlamaktadır.
Kelimelerin kök ve eklerini bulabilen programımız kelime kökünün tipini bizlere gösterebilmektedir. Türkçe yazım denetimi sayesinde de metin içinde bulunan yazım yanlışlarını gösterebilmeyi amaçlamaktadır.
Projemizde artı olarak Doğal Dil İşleme çalışmaları kapsamında özellikler eklenmiştir. Metinlerin kelime ve harf analizlerini yapabilmek için ve Türkçe metinler içerisindeki cümleleri bulmak için yeni yöntemler geliştirilmiştir.
Projemiz Microsoft Visual Studio ortamında C# programlama diliyle yazılmıştır. Ulama bulmak ve Cümle Sonu Bulmak için bizim programımıza özgü yöntemler geliştirilmiştir. Projemizde açık kaynak kodlu Doğal Dil İşleme kütüphanesi olan NZemberek isimli kütüphanenin .Net portu olan NZemberek isimli kütüphane kullanılmıştır.
Programımız büyük bir başarıyla çalışmaktadır.
PROJE ADI
Türkçe Metinlerde Ses Olaylarının Bulunması, Cümle Sonu Belirleme, Metin ve Kelime Analizi
PROJENİN AMACI
Bu projenin amacı, öncelikli olarak Türkçe metinlerde öğrencilerin karşılaştığı ses olaylarının bulunup işaretlenerek öğrencilere yardımcı olmaktır. Türkçe Dilbilgisi eğitiminde öğretilen temel ses olaylarının metin içerisindeki gösterimini kolaylaştırmayı amaçlamaktadır.
Metin analizi, metin tanımlama, imla doğrulama, metindeki kelimeleri türlerine ve öğelerine ayırma, dilin biçimsel analizlerinin yapılması gibi Doğal Dil İşleme uygulama alanında bulunan temel uygulamaları gerçekleştirebilmenin ilk adımı metin içerisindeki cümlelerin bulunmasıdır.
Bu işlem oldukça karışık ve çözülmesi zor bir işlemdir. Bu projede cümle sonu belirleme problemini çözmek için yeni bir yöntem geliştirilmiştir.
Ayrıca projemiz yine metinlerin biçimsel özelliklerinin tespit edilmesine yardımcı olmak adına metinlerin kelime ve harf yoğunluk analizlerinin yapılması ve Kelimelerin kök ve gövdelerinin tespit edilmesini amaçlamaktadır.
GİRİŞ
DOĞAL DİL İŞLEME (DDİ)
Doğal Dil İşleme, yaygın olarak NLP (Natural Language Processing) olarak bilinen Yapay zekâ ve Dil bilimi alt kategorisidir.1 Türkçe, İngilizce, Almanca, Fransızca gibi doğal dillerin (insana özgü tüm diller) işlenmesi ve kullanılması amacı ile araştırma yapan bilim dalıdır.
UZMAN SİSTEMLER VE DOĞAL DİL İŞLEME
NLP yani Doğal Dil İşleme, doğal dillerin kurallı yapısının çözümlenerek anlaşılması veya yeniden üretilmesi amacını taşır. Bu çözümlemenin insana getireceği kolaylıklar, yazılı dokümanların otomatik çevrilmesi, soru-cevap makineleri, otomatik konuşma ve komut anlama, konuşma sentezi, konuşma üretme, otomatik metin özetleme, bilgi sağlama gibi birçok başlıkla özetlenebilir. Bilgisayar teknolojisinin yaygın kullanımı, bu başlıklardan üretilen uzman yazılımların gündelik hayatımızın her alanına girmesini sağlamıştır. Örneğin, tüm kelime işlem yazılımları birer imla düzeltme aracı taşır. Bu araçlar aslında yazılan metni çözümleyerek dil kurallarını denetleyen doğal dil işleme yazılımlarıdır.
Konuşma ve komut anlama yazılımları ise gelecekte insan ve bilgisayar arasındaki klavye, fare gibi veri girişi aygıtlarını ortadan kaldıracak yazılımlardır. Bu gelişmeler makine-insan iletişiminde yeni ve devrimci değişimlere yol açacak ve bilgisayarların daha çok insan tarafından kabul görmesine yol açacaktır.
YAPAY ZEKÂ VE DOĞAL DİL İŞLEME
Gelecekte, konuşma sentezleyiciler ve konuşma anlama alanındaki gelişmeler ve makine-insan iletişiminin gelişmesi, insanın makineden beklentilerini yükseltecektir.
İnsanlar makinelerin kendisini anlamalarını isteyecek, karmaşık kullanımı olan makineler pazar bulamayacaktır. Giderek gelişen ve insanı anlayan makinelerin daha zeki olması insanın yaşam kalitesini yükselteceğinden, vazgeçilmez olması kaçınılmazdır. Zeki makine kavramı, yapay zekâ çalışmalarının hızlanmasına yol açmıştır. Geleceğin en önemli sektörlerinden biri olan yapay zekâ ile insanın iletişim kuracağı tek araç dildir.
Dil, insanoğlunun uygarlaşmasını sağlamakla kalmamış, onun zekâsının doğada daha önce görülmemiş şekilde parlamasını sağlamıştır. Kültür dediğimiz insanlık birikimi, dil kullanan ve iletişim kuran insanın sosyalleşme sürecinin ürünüdür. Dil yeteneği, insan beyninin nasıl çalıştığına ışık tutan insan türüne özgü tek özellik olduğu için dilbilim bilişsel bilimlerde önemli bir yer tutar.
Doğal dilin2 yapısının belirlenmesi, bilgi şifreleme işlemleri, konuşma tanımlama 3, optik karakter belirleme4 , yazı doğrulama5 gibi işlemlerde yardımcı olur. Ayrıca yazılan bir kelimeye göre bir sonraki kelimenin tahmin edilebilmesi özellikle engelli insanların haberleşmesi için çok önemlidir. Ancak bunu yaparken tahmin edilebilen kelime sayısının çok fazla olduğu unutulmamalıdır. Bu nedenle sadece yazıdaki önceden yazılan kelimelere göre gelme olasılığı çok olan kelimeler tahmin edilebilir6. “Doğal Dil İsleme” (DDİ), akademik araştırmalarda ve ticari amaçlarla kullanılmaktadır. DDİ, doğal dili isleyen ve anlayan bir sistemin oluşturulması olarak tanımlanabilir7.
METİN ANALİZİ
DDİ’de derlemi oluşturup kullanan iki çeşit analiz bulunmaktadır; Biçimbilimsel ve istatistiksel Analiz8. Biçimbilimsel analiz, cümle sonu belirleme, kelime türlerini (isim, sıfat, vb.) belirleme ve kelimelerin parçalarını (kök, ek, vb.) analiz etme gibi kelimelerin biçimsel durumlarını inceler. İstatistiksel analiz iki türlü yapılabilir; harfler ve kelimeler üzerine. Sesli ve sessiz harflerin dizilimi, harflerin ngram analizleri, harfler arasındaki ilişkiler, vb. harfler üzerinde yapılabilen analizlerdir, buna “Harf Analizi” denir. Bir kelimedeki harf sayısı, kelimelerin n-gram frekansları, kelimelerin cümle içindeki dizilimi gibi analizler kelime üzerinde yapılabilir ve “Kelime Analizi” olarak adlandırılır.
Derlemin bazı tanımları aşağıda verilmiştir:
- Derlem, dilbilimsel bilginin koleksiyonudur, yazılı ya da kaydedilen konuşmalar seklinde olabilir9.
- Doğal olarak meydana gelen metinlerden dilin çeşitliliğini ve durumunu belirlemek amacıyla seçilen ve bir araya getirilen metinler10.
- Doğal dil isleme alanında kullanılmak için yazılardan oluşturulmuş özel bir veri tabanıdır ve kelimeleri hızlı şekilde bulma ve isleme gibi özel işlemleri yapmaya izin verir.
TÜRKÇE METİNLERDE CÜMLE SONU BULMA
Birçok doğal dil isleme işlemlerinde, cümle sonu belirleme işi ilk şarttır. Kullanılabilen doğal dil isleme araçlarının çoğu cümle sonu belirleme isini güvenilir olarak yapmaz.
Cümle sonu işaretlerinin (“.”, “!” gibi) kullanılarak cümle sonunun belirlenmesi mümkündür. Ancak bazı işaretler kısaltmalar ve bunun gibi bazı işaretleri (eposta adresleri, numaralandırma gibi) göstermek için de kullanılabilir. Aşağıda bazı örnekler görülmektedir:
- Cumartesi aksam 5 p.m.’de geldi.
- cs.deu.edu.tr okulumuzun web sitesidir.
- E-posta adresi bilgi@cs.deu.edu.tr ‘dir.
Bunlar cümle sonu bulma işlemlerinde karmasa yaratan bazı durumlardır. Tüm diğer dillerde de bu gibi durumlar mevcuttur ve cümle sonu belirleme işlemlerini zorlaştırmaktadır. Bu projemizde Türkçe için cümle sonu belirme işlemini doğru şekilde yapabilecek yeni bir algoritma geliştirilmiştir.
Projemiz ile Türkçe Doğal dilinin bilgisayar ortamında tarafından daha iyi anlaşılıp analiz edilmesini sağlamak amacıyla farklı fonksiyonlar geliştirdik.
TÜRKİYE TÜRKÇESİNDEKİ SES OLAYLARI
Kelimelerde zamana ve sahaya bağlı olarak sürekli değişmelerin, gelişmelerin olması dilin canlılığının bir göstergesidir.11 Dil durağan değil, dinamik bir yapıya sahiptir. Dilin söz varlığını oluşturan kelimelerdeki sesler, heceleri ve kelimeleri oluştururken tarihî süreç içerisinde düşerler, yer değiştirirler, türerler, başka seslere benzerler. İşte bütün bunlar, ses olayları başlığı altında incelenir. Dilde ses olayları, çeşitli sebeplerden kaynaklanır. Bunlardan başlıcaları aşağıda özetlenmiştir:
SES OLAYLARININ SEBEPLERİ
- Dilin ses özellikleri: Türkçede kelime sonunda b, c, d, g sesleri olmadığı için Arapça kitâb kelimesi Türkçeye kitap şeklinde geçmiştir. Uzun ünlü olmadığı için de â ünlüsü kısalarak normal a’ya dönüşmüştür.
- Başka seslerin etkisi: Bazı sesler, yanlarındaki diğer seslere etki ederek onları kendilerine benzetirler, değiştirirler. Meselâ, anbar kelimesindeki b sesi, yanındaki n’ye etki ederek onu, kendisi gibi dudak ünsüzü olan (m) yapmıştır. Böylece kelime, ambar şekline dönüşmüştür. Yaşıl kelimesinin yeşil’e dönüşmesinin sebebi, y ve ş seslerinin inceltici etkisidir.
- Vurgu: Türkçede orta hece vurgusu genellikle zayıf olduğu için bu hecedeki ünlüler bazen daralır bazen de düşerler: Tasarıla> tasarla, besileme> besleme, yalınız > yalnız vb. gibi.
ç) Zayıf sesler: ğ, h, ı, l, n, r, y, z sesleri zayıf sesler olduğu için bazı ses olaylarına sebep olurlar: ağabey > âbi, hastahane > hastane, pek iyi > peki, bir daha> bi daha, soğan> soan, uğur> uur, ınanmak > inanmak.
- Söyleyiş güçlüğü ve kakofoni: Bazı seslerin yan yana gelmesi söyleyiş güçlüğüne veya kakofoniye sebep olur. Bu durumda bazı ses olayları olur: büyükcek > büyücek, küçükçük > küçücük, ufakcık > ufacık.
Ses olaylarının sebebini, dildeki en az emek yasasına bağlamak mümkündür. Günümüzde ses olayları insanların kelimeleri daha az çaba sarf ederek kullanmasıyla oluşur. Çalışmamızda 3 temel ses olayının metin üzerinde gösterilmesini sağladık. Bu 3 temel ses olayı Ulama, Ünlü Daralması ve Ünsüz Sertleşmesi olaylarıdır.
YÖNTEM
Projemiz birçok farklı fonksiyondan oluşmaktadır. Aşağıda bu fonksiyonların ne işe yaradıkları ve işlem adımları yazılmıştır.
TÜRKÇE METİNLERDE ULAMA BULMA FONKSİYONU
ULAMA NEDİR?
Bir cümlede ünsüzle biten bir sözcükten sonra ünlüyle başlayan bir sözcük gelirse (konuşma dilinde) birinci sözcüğün ünlüsü, ikinci sözcüğün ünlüsüyle bitiştirilerek söylenir. Buna ulama denir. Bunun nedeni ünlünün çekim gücüdür.12
- Ulama bir söyleyiş güzelliği ve akıcılığı yaratır. Bu uygulama yazı diline geçmez.
- Ulama aruz ölçüsünde kapalı bir heceyi kısa hece yapmaya yarar.
- Bileşik sözcüklerin oluşumunda ulama varsa sözcük hecelerine ayrılırken bu ilke gözetilir.
Örnekler :
Bir ay önce gelen adamın adı neydi ?
Bu cümle konuşma dilinde:
Birayönce gelenadamınadı neydi ?
Beklenenolay sonunda patlak verdi.
Evimizinarkasında bodurağaçlar vardı.
Bahçemizde çeşitli ağaçlar ve hanımelleri vardı.
Bu cümledeki “hanımeli” sözcüğü de ulama özelliğine sahip bir bileşik sözcüktür. “Hanım + eli” Bu nedenle hecelerine ayrılırken bu özellik dikkate alınır : ha – nı – me – li.
Aslanağzı ® as – la – nağ – zı (Aslan + ağzı)
Kırklareli ® Kırk – la – re – li (Kırklar + eli)
ULAMA BULMA ALGORİTMASI :
Türkçe metinlerdeki ulama olaylarının bulunması için aşağıdaki adımlar takip edilmiştir.
- Program içindeki metin giriş alanını kontrol et.
- Eğer metin alanı boş ise Adım 13’e git
- Metin alanındaki yazıyı boşluk karakterine göre parçalara ayır
- Her boşluğun solundaki ilk karakterin sessiz harf olup olmadığını kontrol et
- Her boşluğun sağındaki ilk karakterin sesli harf olup olmadığını kontrol et
- Eğer şartlar tutuyorsa boşluğun solundaki ilk boşluğa kadar olan harf dizisini ve sağındaki ilk boşluğa kadar olan harf dizisini bir diziye ata
- Dizi içindeki tüm karakter dizileri sayısınca döngü oluştur
- Dizi içindeki karakter dizileri program içindeki metin alanında varsa onları yeni bir dizi içine ata
- Yeni dizi içindeki eleman sayısınca döngü oluştur.
- Yeni dizi içindeki karakter dizilerini metin alanı içinde bul
- Bulunan Karakter Dizilerini listeye ekle
- Bulunan karakter dizilerinin metin alanı içinde rengini ve font özelliklerini değiştir.
- Dizi sona ulaşmadıysa 7. Adıma Git
- Fonksiyonu bitir.
SONUÇ
Ulama bulma fonksiyonumuz %100 çalışmaktadır. Türkçe bir metin içerisindeki tüm ulama olaylarını başarıyla bulup, metin içinde renklendirme yapabilmektedir. Çıktı ekranına ulama olan kelimeleri listeleyebilmekte ve istenirse çıktı ekranının kaydedilmesi başarıyla gerçekleşmektedir.
ULAMA BULMA UYGULAMASI SONUÇLARI ULAMA ÖRNEĞİ
Bilge sorar: ” Geceyle gündüzü nasıl ayırırsınız? ” Öğrencilerden biri, ” Uzaktan koyunu keçiden ayıramadığım zaman akşam olmuş demektir.” Başkası, ”İncir ağacını, zeytin ağacından ayırdığım zaman sabah başlamıştır. ”Bilgeye kendisinin ne düşündüğünü sormuşlar. O da şunu demiş:
Yürürken karşıma bir kadın çıktığında, güzel mi, çirkin mi, siyah mı, beyaz mı, diye ayırmadan, ona kız kardeşim diyebildiğimde ve yine yürürken yoluma çıkan erkeği, yoksul mu, zengin mi diye bakmadan, milletine, ırkına, dinine aldırmadan kardeşim sayabildiğimde anlarım ki sabah olmuştur, aydınlık başlamıştır.
İŞLEM YAPILDIKTAN SONRAKİ METİN ALANI
Bilge sorar: ” Geceyle gündüzü nasıl ayırırsınız? ” Öğrencilerden biri, ” Uzaktan koyunu keçiden ayıramadığım zaman akşam olmuş demektir.” Başkası, ”İncir ağacını, zeytin ağacından ayırdığım zaman sabah başlamıştır. ”Bilgeye kendisinin ne düşündüğünü sormuşlar. O da şunu demiş:
Yürürken karşıma bir kadın çıktığında, güzel mi, çirkin mi, siyah mı, beyaz mı, diye ayırmadan, ona kız kardeşim diyebildiğimde ve yine yürürken yoluma çıkan erkeği, yoksul mu, zengin mi diye bakmadan, milletine, ırkına, dinine aldırmadan kardeşim sayabildiğimde anlarım ki sabah olmuştur, aydınlık başlamıştır.
ULAMA BULMA FONKSİYONU ÇIKTI EKRANI

TÜRKÇE METİNLERDE ÜNLÜ DARALMASI BULMA FONKSİYONU
ÜNLÜ DARALMASI NEDİR?
Ünlü daralması, Türkçedeki ses olaylarından biridir. “a, e” düz-geniş ünlüleriyle biten sözcükler “-yor” eki ile çekimlendiğinde sözcüğün son hecesinde bulunan geniş ünlüler “ı, i, u, ü” dar ünlülerine dönüşür:13
- sakla + yor > saklıyor
- dile +yor > diliyor
- kutla + yor > kutluyor
-yor ekinden önce gelen -me olumsuzluk ekindeki e ünlüsü her zaman daralır:
- gelme + yor > gelmiyor
- öpme + yor > öpmüyor
- yazma + yor > yazmıyor
y kaynaştırma ünsüzünden önce gelen “a, e” düz-geniş ünlülerinde daralma meydana gelmez:
- boyayacak
- saklayacak
- dileyen
- kutlayalım
- anlayabilir
Ancak “demek” ve “yemek” eylemlerinin gelecek zaman kipi daralmış şekilde yerleşmiştir:
- de + y + ecek > diyecek
- ye + y + ecek > yiyecek
ÜNLÜ DARALMASI BULMA ALGORİTMASI :
Türkçe metinlerdeki ünlü daralması olaylarının bulunması için aşağıdaki adımlar takip edilmiştir.
- Program içindeki metin giriş alanını kontrol et.
- Eğer metin alanı boş ise Fonksiyonu bitir
- Metin alanındaki yazıyı boşluk, nokta, virgül, ünlem, soru işareti karakterlerine göre parçalara ayır
- Tüm parçaları kelimeler isminde bir diziye ata.
- Kelimeler dizisindeki eleman sayısınca döngü oluştur.
- Sıradaki kelimesi elemanını eleman isimli değişkene ata
- Dizi elemanını Türkçe olup olmadığını kontrol et
- Türkçe değilse diğer dizi elemanına geç
- Kelimenin eklerini ekler dizisine ata
- Kelimenin kökünü kök değişkenine ata
- Eğer ekler dizisi “Şimdiki Zaman IYOR” ekini içermiyorsa 14 Adıma git
- Eğer Ekler Dizisi “Olumsuzluk ME” ve “Şimdiki Zaman IYOR” ekini içeriyorsa, Eleman’ı Boya
- Bulunan Karakter Dizilerini listeye ekle
- Eğer Kök değişkeni ‘a’ veya ‘e’ karakteri ile bitiyorsa, Eleman’ı Boya
- Eğer Kelime “yiyecek” veya “diye” ise, Eleman’ı Boya
- Eğer kök “de” veya “ye” ise kelimenin ikinci harfini son harf değişkenine ata
- Eğer kelimenin ikinci harfi “e” veya “a” değilse, Eleman’ı Boya
- Fonksiyonu Bitir
SONUÇ
Ünlü daralması fonksiyonumuz Türkçe metinlerin içerisinde yer alan ünlü daralmalarını büyük bir başarıyla bulabilmektedir. Ancak bazı kelimelerin cümle içerinde niye kullanıldıklarını ve anlamları bilinmeden daralma olup olmadığını tespit etmek imkansızdır. Örneğin “diliyor” kelimesinde eğer dilmek manasında kullanılırsa ünlü daralması yok fakat dilemek manasında kullanıldığında ünlü daralması meydana gelir. Bu tarz kelimelerin ses olaylarını bulunamamıştır. Bu tarz istisnalar olabildiğinden bunları program kullanıcıları göz ardı etmemelidir.
Bir kelimeyi köklerini ve eklerini bulmak için kokBul ve ekler isimli iki farklı fonksiyon kullanılmıştır. Metin alanı içerisindeki karakter dizisini boyamak içinse ise Boya isimli bir fonksiyon kullanılmıştır. Bir kelimenin Kök ve eklerini bulmak için nZemberek Kütüphanesi kullanılmıştır.
ÜNLÜ DARALMASI UYGULAMASI SONUÇLARI
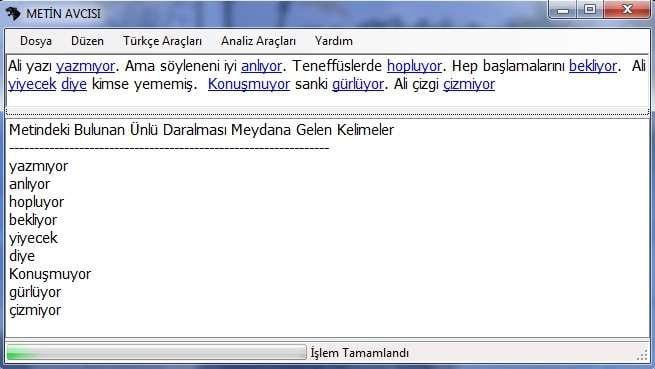
ÜNLÜ DARALMASI ÖRNEĞİ
Ali yazı yazmıyor. Ama söyleneni iyi anlıyor. Teneffüslerde hopluyor. Hep başlamalarını bekliyor. Ali yiyecek diye kimse yememiş. Konuşmuyor sanki gürlüyor. Ali çizgi çizmiyor.
İŞLEM YAPILDIKTAN SONRAKİ METİN ALANI
Ali yazı yazmıyor. Ama söyleneni iyi anlıyor. Teneffüslerde hopluyor. Hep başlamalarını bekliyor. Ali yiyecek diye kimse yememiş. Konuşmuyor sanki gürlüyor. Ali çizgi çizmiyor.
ÜNLÜ DARALMASI ÇIKTI EKRANI
TÜRKÇE METİNLERDE ÜNSÜZ SERTLEŞMESİ OLAYLARININ BULUNMASI
ÜNSÜZ SERTLEŞMESİ NEDİR?
Ünsüz sertleşmesi Türkçedeki ses olaylarından biridir. Bu kurala göre sert ünsüzle biten kelimeler b, c, d, g ünsüzleriyle başlayan bir ek aldığında, ekin bu ilk ünsüzü sertleşerek p, ç, t, k ünsüzlerinden birine dönüşür:14
dolap+da > dolapta, aç+dı > açtı, kitap+cı > kitapçı, bit+gin > bitkin, 15+de > 15’te, Türk+ce > Türkçe
Türkçede ünsüzler (sessiz harfler) sert ve yumuşak olmak üzere iki gruba ayrılır. Sert ünsüzler ç, f, h, k, p, s, ş ve t’dir. Bu harf grubunu öğrencilerin ezberlemesini kolaylaştırmak için “f ı s t ı k ç ı ş a h a p” ifadesi üretilmiştir. Bu kelime grubundaki ünsüz harflerin tamamı serttir. Bunun dışında kalanlar ise yumuşak ünsüzlerdir.
Sert ünsüzler
ç, f, h, k, s, ş, t, p
Yumuşak ünsüzler
b, c, d, g, ğ, j, l, m, n, r, v, y, z
Bağlaç olan “de” ve “da” ayrı yazıldığı için yazımda ünsüz sertleşmesi kuralına uymaz. Ancak kurala uymuş gibi telaffuz edilebilir:
Bahçeden meyve-sebzenin yanı sıra annem için çiçek de topladım.
İstisnâlar
Belirli bir kişiyi referans alarak o kişi etrafındaki insan gruplarını veya biyolojide hayvan ve bitki sınıflarını belirtmek için kullanılan “-gil” eki sertleşerek “-kil”e dönüşmez.
Muratgil, köpekgiller
ÜNSÜZ SERTLEŞMESİ BULMA ALGORİTMASI :
Türkçe metinlerdeki ünsüz sertleşmesi olaylarının bulunması için aşağıdaki adımlar takip edilmiştir.
- Program içindeki metin giriş alanını kontrol et.
- Eğer metin alanı boş ise Fonksiyonu bitir
- Metin alanındaki yazıyı boşluk, nokta, virgül, ünlem, soru işareti karakterlerine göre parçalara ayır
- Tüm parçaları kelimeler isminde bir diziye ata.
- Kelimeler dizisindeki eleman sayısınca döngü oluştur.
- Sıradaki kelimesi elemanını eleman isimli değişkene ata
- Dizi elemanını Türkçe olup olmadığını kontrol et
- Türkçe değilse diğer dizi elemanına geç
- Kelimenin eklerini ekler dizisine ata
- Kelimenin kökünü kök değişkenine ata
- Kelimenin kökünden sonra gelen İlk harfi ilkHarf değişkenine ata
- Kelimenin kökünün son Harfi ‘f’, ‘s’, ‘t’, ‘k’, ‘ç’, ‘ş’, ‘h’, ‘p’ harflerinden biri değilse 15 Adıma git
- ilkHarf değişkeni ‘ç’, ‘t’, ‘k’ harflerinden biri değilse 15 Adıma git
- eleman isimli değişkeni boya.
- Fonksiyonu bitir
SONUÇ
Ünsüz sertleşmesi fonksiyonu ile Türkçe metinler içerisinde var olan ünsüz sertleşmesi olayları başarı ile bulunabilmektedir.
Ancak bazı yapım eki alan kelimeleri yeni bir kelime olarak algıladığından bunların içerisindeki ses olaylarını bulamamıştır. Kullandığımız NZemberek kütüphanesinin bazı yapım eki alan kelimelerin eklerini bulamamasından kaynaklanan bu duruma “atkı” kelimesi örnek verilebiliriz. “atkı” kelimesinde “–gı” yapım eki var olduğu halde kelimenin ek ve köklerini ayıramamıştır. Bu durumda bu kelimedeki ses olayının bulunamamasına yol açmıştır.
“Atkı” kelimesinin NZemberek tarafından bulunan olası çözümleri aşağıdaki gibidir. KELİME İNCELEME RAPORU
—————————————————-
atkı kelimesi için olası çözümler
ÇÖZÜM :
KÖKÜ atkı
Tipi: Tür İsmi
Ek 0 = ISIM_KOK
Bir kelimeyi köklerini ve eklerini bulmak için kokBul ve ekler isimli iki farklı fonksiyon kullanılmıştır. Metin alanı içerisindeki karakter dizisini boyamak içinse ise Boya isimli bir fonksiyon kullanılmıştır. Bir kelimenin Kök ve eklerini bulmak için nZemberek Kütüphanesi kullanılmıştır.
ÜNSÜZ SERTLEŞMESİ UYGULAMASI SONUÇLARI
ÜNSÜZ SERTLEŞMESİ ÖRNEĞİ
Kavga eden çocuklar öğrenmeni görünce yavaşça uzaklaştılar.
Sırada ayakta beklemekten ayaklarım ağrıdı.
Bu güzel pastaları annem yaptı.
Kar yağışı önümüzdeki günlerde tüm yurtta etkisini gösterecek.
İŞLEM YAPILDIKTAN SONRAKİ METİN ALANI
Kavga eden çocuklar öğrenmeni görünce yavaşça uzaklaştılar.
Sırada ayakta beklemekten ayaklarım ağrıdı.
Bu güzel pastaları annem yaptı.
Kar yağışı önümüzdeki günlerde tüm yurtta etkisini gösterecek.
ÜNSÜZ SERTLEŞMESİ FONKSİYONU ÇIKTI EKRANI
KELİME İNCELEME
Kelime İnceleme fonksiyonu bize metin alanı içinde sicili olan kelimenin olası çözümlerini göstermektedir. Kelimenin köklerini ve bu köke gelen ekleri, kökün tipini, eklerin çeşitlerini göstermektedir. Bir kelimenin birden fazla kökü olabilir. Kök yapım eki alarak başka bir kelime oluşturmuş olabilir. Fonksiyonumuz sayesinde kelimenin olası tüm çözümleri bulunmaktadır.
Örneğin “diliyor” kelimesi için programımız bize aşağıdaki sonuçları döndürecektir.
KELİME İNCELEME RAPORU
—————————————————
diliyor kelimesi için olası çözümler
ÇÖZÜM :
KÖKÜ dil Tipi: FIIL
Ek 0 = FIIL_KOK
Ek 1 = FIIL_SIMDIKIZAMAN_IYOR
—————————————
ÇÖZÜM :
KÖKÜ
dile
Tipi: FIIL
Ek 0 = FIIL_KOK
Ek 1 = FIIL_SIMDIKIZAMAN_IYOR
—————————————
Görüldüğü gibi kelimenin 2 farklı kökü vardır. İki kök için farklı tiplerde ekler almıştır.
- Kökler, kelimelerin anlamlı parçalarıdır. Meselâ bakış kelimesinde bak köktür. Bakma işinin anlamı bak kökü üzerindedir. Buradan bakma işi anlamını çıkarıyoruz.
- Kökler, kelimelerin parçalanamayan kısımlarıdır. Meselâ bak kökü daha fazla parçalanamaz. Parçalanırsa bakmakla ilgili anlamı ortadan kalkar.
- Kökler varlıkların ve hareketlerin yalın karşılıklarıdır. Onları bir zaman, şahsa bağlamazlar, soyut olarak ifade ederler.
- Kökler, kelimelerin çekirdekleridir. Meselâ gözlemek, gözlem, gözcü, gözcülük, gözlük kelimeleri hep göz kökünden türetilmiştir.
GÖZ= gözlemek, gözlem, gözcü, gözcülük, gözetmen, gözlük, gözlükçü, gözlükçülük, gözlü, gözsüz…..
- Her varlık veya hareket için dilde bir kök yoktur. Birbirine yakın varlık veya kavramlar aynı kök etrafında yapılan kelimelerle karşılanır. Meselâ ver kökünden vergi, verim, verimli, verecek, verimlilik gibi.
- Kökler eskiden beri var olan ve sonradan yapılamayan dil birlikleridir. Yeniden kök yapılamaz. Ancak yabancı dillerden yeni kökler alınabilir. Radyo-cu, radyo culuk vb.
- Dilde iki çeşit kök vardır: isim kökleri, fiil kökleri. Çünkü kâinatta iki çeşit varlıktan söz edebiliriz:
A- Nesne B- Hareket
İnsan, hayvan, bitki, dağ, orman, taş, toprak, duygu, akıl, hastalık vb. nesnelerdir. Bunların gelmesi, gitmesi, yanması, büyümesi, tükenmesi vs. Hareketlerdir. İşte nesneler isimlerle, hareketlerle fiillerle karşılanmaktadır.
KELİME İNCELEME UYGULAMASI SONUÇLARI
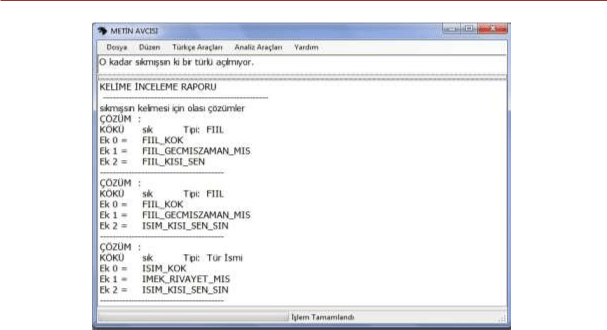
METİN ALANI
Sıkmışsın kelimesi için çözümler
KELİME İNCELEME FONKSİYONU ÇIKTI EKRANI
YAZIM DENETİMİ
Yazım denetimi bir metinde veya bir cümledeki yazım hatalarını bulmaktadır. Yazım denetimi fonksiyonu nZemberek Doğal Dil İşleme Kütüphanesi kullanılarak geliştirildi. Temel olarak nZemberek kütüphanesinde yer alan Türkçe Kelime listesini baz alarak yazım denetimi yapılıyor.
Kelime denetimine ek olarak fonksiyonumuz yanlış yazılmış kelimeleri bulduğu gibi noktalama işaretlerinden sonra boşluk bırakma kuralını da denetler. Eğer noktalama işaretinden sonra boşluk bırakılmadıysa o kelime grubunu hatalı olarak işaretlemektedir.
Türk Dil Kurumunun Yazım ve Dil Bilgisi kurallarına göre: ”Duygu ve düşünceleri daha açık ifade etmek, cümlenin yapısını ve duraklama noktalarını belirlemek, okumayı ve anlamayı kolaylaştırmak, sözün vurgu ve ton gibi özelliklerini belirtmek üzere noktalama işaretleri kullanılır.
Noktalama işaretlerinden nokta, virgül, noktalı virgül, iki nokta, üç nokta, soru, ünlem, tırnak, ayraç ve kesme işaretleri ait oldukları kelimelere bitişik olarak yazılır ve kesme dışındaki işaretlerden sonra bir harf boşluğu ara verilir.15”
KELİME DENETLEME FONKSİYONU ALGORİTMASI:
Türkçe metinlerdeki kelimelerin Türkçe yazım kurallarına uygunluğunu tespit etmek için aşağıdaki adımlar takip edilmiştir.
- Program içindeki metin giriş alanını kontrol et.
- Eğer metin alanı boş ise Fonksiyonu bitir
- Metin alanındaki yazıyı boşluk karakterlerine göre parçalara ayır
- Tüm parçaları kelimeler isminde bir diziye ata.
- Kelimeler dizisindeki eleman sayısınca döngü oluştur.
- Sıradaki kelimesi elemanını eleman isimli değişkene ata
- Eleman değişkeninin büyüklüğü 1 den küçükse 16 Adıma git
- Eleman değişkeni sayı ise 16 Adıma git
- Eleman değişkenini son karakterini sonkarakter isimli değişkene ata
- Eleman Değişkeninin ilk karakterini ilkKarakter isimli değişkene ata
- Eğer SonKarakter (“.”,”,”,”!”,”?”,”’”,””) ise son karakteri sil
- Eğer ilk karakter (“””,”(“,”[“) ise ilk karakteri sil
- Kelimeyi küçük harfe döndür
- Eğer Kelime Denetimi sonucu doğru ise 16 adıma git
- Kelimenin rengini ve fontunu değiştir.
- Bitir
YAZIM DENETİMİ UYGULAMASI SONUÇLARI
YAZIM DENETİMİ ÖRNEĞİ
Çin’in kırsal kesiminde yaşam savaşı veren bir aile vardı. Dede,baba, anne ve çocuktan oluşan bu aile oldukça sıkıntı çekiyordu.
Bir gün baba, yılların verdiği yorgunlukla bir köşede oturmakdan başka işe yaramayan dedeyi, pazar küfesine koyarak nehre doğru yola çıktı.Nehrin kenarında arkadaşlarıyla oynayan çocuk, babasına ne yaptığı sordu.
İŞLEM YAPILDIKTAN SONRAKİ METİN ALANI
Çin’in kırsal kesiminde yaşam savaşı veren bir aile vardı. Dede,baba, anne ve çocuktan oluşan bu aile oldukça sıkıntı çekiyordu.
Bir gün baba, yılların verdiği yorgunlukla bir köşede oturmakdan başka işe yaramayan dedeyi, pazar küfesine koyarak nehre doğru yola çıktı.Nehrin kenarında arkadaşlarıyla oynayan çocuk, babasına ne yaptığı sordu.
YAZIM DENETİMİ FONKSİYONU ÇIKTI EKRANI

TÜRKÇE METİNLERDE CÜMLE SONU BELİRLEME UYGULAMASI
Bir derlemi oluşturmanın ilk basamağı “cümleleri bulmak” tır. Genel olarak Türkçe cümlelerin ., …, !, ? gibi işaretlerle bittiği bilinse de cümle sonu bulma işlemi bazı belirsizlikler sebebiyle çok karışık ve zor bir işlem haline gelmektedir. Örneğin;
- Uluslar, bu ekonomik buhran sonucunda 2. Dünya Savaşı’nı yasamıştır.
- Bu sezon kaybedilen maç sayısı 2. Dünya Kupası’na katılma sansı azalıyor.
İlk cümlede “.” karakteri sıralama için kullanılırken ikinci cümlede cümle sonunu belirtmektedir. Ancak her iki cümlede de “.” işaretinden sonra büyük harf bulunmaktadır.
Yeni geliştirilen cümle sonu bulma yönteminde bu belirsizliklerin çözülebilmesi için kural tabanlı bir yaklaşım denenmiştir.
Cümle sonu belirleme için oluşturduğumuz kural listesi aşağıdaki gibidir.
Tablo 1 Cümle sonu belirleme için oluşturulan kural listesi
| Cümle Sonu | Kurallar |
| Dogru | L. U |
| Dogru | L. # |
| Dogru | L. ‘ |
| Dogru | L. “ |
| Dogru | L. [ |
| Dogru | L. ( |
| Dogru | L. + |
| Dogru | L. – |
| Yanlış | U. U |
| Yanlış | #. U |
| Yanlış | L. L |
| Yanlış | ?.? (Noktadan Sonra Boşluk yok) |
| Yanlış | #. # |
| Yanlış | ?. ” |
| Yanlış | #. , |
| Yanlış | #. ) |
| Yanlış | #. ] |
Cümle sonu kural listesi Tablo 1’de gösterildiği gibi üçlü grup seklinde (“L. U” gibi) oluşturulmuştur.
Ortadaki “.” (nokta) karakteri cümle sonu işaretini (“.”,”!”,”?”,”…”,”:”) göstermektedir. Yani tablodaki “.” (nokta) işareti yerine cümle sonu bildiren diğer işaretlerden (“.”,”!”,”?”,”…”,”:”) herhangi biri getirilebilir. Sol taraftaki karakter noktalama işaretinden önceki kelimenin ilk karakterinin durumunu, sağ taraftaki karakter ise işaretten sonraki kelimenin ilk harfinin durumunu göstermektedir. Tüm kurallar cümle sonu bildiren işaretten sonra boşluk olması durumunu şart koşmaktadır. Tablo 2’de kural listesindeki işaretlerin anlamları gösterilmiştir.
Tablo 2 Kural listesindeki işaretlerin anlamları
| Karakter | Anlamı |
| . | Cümle sonu isaretleri (. … ! ? ) |
| L | Küçük harf (Lowercase) |
| U | Büyük harf (Uppercase) |
| # | Sayı |
| ? | Herhangi karakter (ne olursa olsun) |
| – | – |
| , | , |
| ( | ( |
| ) | ) |
| / | / |
| ‘ | ‘ |
| “ | “ |
Bu kurallar oluşturulurken Türkçe dilinin özelliklerinden kaynaklanan zorluklar ortaya çıkmıştır ve çözümlenmeye çalışılmıştır.
Aşağıda Türkçe cümlelerin sonlarının bulunması sırasında belirsizlik yaratan bazı durumlar örneklendirilmiştir:
- Cumhuriyetimizin 75. yılı coşkuyla kutlandı.
- Tahta çıkan IV. Murat emirler yağdırdı.
- Olimpiyatlar için uzun zamandır çalışan
- Ahmet koşuda 2., uzun atlamada ise ancak 4. olabildi.
- Mehmet YILDIZ size uğradı.
- Dr. Mehmet YILMAZ konuşmasını 12.12.2014 tarihinde yapacak.
İlk cümlede “.” işaretinden sonra cümle bitmemektedir. “.” işareti sıralama belirmek amacıyla kullanılmıştır. Dördüncü cümlede “A” harfi kısaltma olarak kullanılmıştır. 6. cümledeki kısaltmalar ve tarih ayracı olarak kullanılan nokta işaretleri de cümle sonu belirtmemektedir.
Bunun gibi, cümlelerde belirsizlik yaratan kısaltmalar için Şekil 1’te görülebileceği gibi kısaltmalıların yer aldığı bir dizi oluşturulmuştur.
Şekil 1 Kısaltma Dizisi
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Türk_Cümle_PARSER.Sınıflar
{
class kisaltmaListesi
{
public string[] _kisaltmalar = new string[]
{
"age.",
"agm.",
"agy.",
"Alb.",
"Alm.",
"anat.",
"ant.",
"Apt.",
"Ar.",
"ark.",
"Arş.","Gör.",
"As.",
"As.","İz.",
"Asb.",
"astr.",
"astrol.",
"Atğm.",
"atm.",
"Av.",
"bağ.",
"Bçvş.",
"bit.","b.",
"biy.",
"bk.",
"bl.",
"Bl.",
"Bn.",
"Bnb.",
"bot.",
"Böl.",
"bs.",
"Bşk.",
"Bul.",
"Bulg.",
"Cad.",
"coğ.",
"Cum.","Bşk.",
"çev.",
"Çvş.",
"db.",
"dil","b.",
"dk.",
"Doç.",
"doğ.",
"Dr.",
"drl.",
"Dz.","Kuv.",
"Dz.","Kuv.","K.",
"dzl.",
"Ecz.",
"ed.",
"e.",
"ekon.",
"Ens.",
"Erm.",
"f.",
"Fak.",
"Far.",
"fel.",
"fil.",
"fiz.",
"fizy.",
"Fr.",
"Gen.",
"geom.",
"gn.",
"Gnkur.",
"Gön.",
"gr.",
"hay.","b.",
"haz.",
"hek.",
"hlk.",
"Hs.","Uzm.",
"huk.",
"Hv.","Kuv.",
"Hv.","Kuv.","K.",
"Hz.","öz.",
"Hz.",
"İbr.",
"İng.",
"is.",
"İsp.",
"işl.",
"İt.",
"Jap.",
"jeol.",
"kim.",
"koor.",
"Kor.",
"Kora.",
"Korg.",
"kr.",
"krş.",
"Kur.",
"Kur.","Bşk.",
"Lat.",
"Ltd.",
"Mac.",
"Mah.",
"man.",
"mat.",
"Md.",
"mec.",
"mim.",
"min.",
"Müh.",
"Mür.",
"müz.",
"No.",
"Nö.",
"Nö.","Sb.",
"Okt.",
"Onb.",
"Opr.",
"Or.",
"Ora.",
"Ord.",
"Org.",
"Ort.",
"Osm.","T.",
"öl.",
"ör.",
"öz.",
"ped.",
"Port.",
"Prof.",
"psikol.",
"Rum.",
"Rus.",
"s.",
"sa.",
"Sb.",
"SEFD","Bşk.",
"sf.",
"Sl.",
"Sn.",
"snt.",
"Sok.",
"sos.",
"sp.",
"Srp.",
"Şb.",
"T.",
"T.C.",
"tar.",
"Tb.",
"tek.",
"tel.",
"telg.",
"Tğm.",
"tic.",
"tiy.",
"tlks.",
"tls.",
"Top.",
"Tug.",
"Tuğa.",
"Tuğg.",
"Tüm.",
"Tüma.",
"Tümg.",
"Uzm.",
"Üçvş.",
"ünl.",
"Ütğm.",
"vb.",
"vd.",
"Vet.",
"vs.",
"Y.","Mim.",
"Y.","Müh.",
"Yay.",
"Yb.",
"Yd.","Sb.",
"Yrd.",
"Yrd.","Doç.",
"Yun.",
"yy.",
"Yzb.",
"zf.",
"zm.",
"zool.",
"St.",//Sonradan Tespit Edilip Eklenen kısaltmalar
"Sh.","Yd.","İnş.","Tic.", "Bkz.","Tur.","İşl","San.","Yat.","İst."};
}
}
Bu dizi kullanılarak yazılar cümlelere daha verimli biçimde ayrılabilmektedir. Ayrılan cümleler yine metin dosyaları biçiminde kaydedebilmektedir.
CÜMLE SONU BULMA ALGORİTMA ADIMLARI:
- Program içindeki metin giriş alanını kontrol et.
- Eğer metin alanı boş ise Fonksiyonu bitir
- Metin alanındaki yazıyı boşluk karakterlerine göre parçalara ayır
- Tüm parçaları kelimeler isminde bir diziye ata.
- Kelimeler dizisindeki eleman sayısınca döngü oluştur.
- Sıradaki kelimesi elemanını eleman isimli değişkene ata
- Eleman değişkeninin değeri Kısaltma dizisinde yoksa 9. Adıma git
- Eleman değişkenini karakter ekle
- Kelimeler dizisinin sonuna gelmediyse 5. Adıma git
- Kurallar tablosuna göre cümle ayırma işlemini gerçekleştir
- Cümleleri Listeye yazdır
- Bitir
SONUÇ
Cümle sonu bulma fonksiyonu tam bir başarı ile çalışmaktadır. Türkçe bir metin içerisinde, yazım kurallarına uygun yazılmış tüm cümleleri başarı ile ayırt edebilmektedir. Türk Dil Kurumunun yazıl ve dil bilgisi kuralları çerçevesinde Türkçe cümle sonu belirten noktalama işaretlerini tespit edebilmektedir. Yine cümle içerisindeki sayı, tarih gibi normalde cümle sonu olmadığı halde kullanılan işaretleri de anlayıp cümleyi bitirmemektedir. Cümle içerisinde kısaltmaları tespit ederek kısaltmaların sonundaki noktalama işaretlerini de cümle sonu olarak görmemektedir. Cümle içindeki tırnak işaretleriyle yazılı alt cümleleri de cümleden ayırmadan sadece ana cümleyi ayırt edebilmektedir.
Cümle sonu bulma işlemini tamamen kendi uygulamamıza özel kendi geliştirdiğimiz kısa fakat etkili bir algoritma ile gerçekleştiriyoruz. Metin içindeki kısaltmaları bulup işaretledikten sonra tek satırlık bir REGEX kodu ile tablo 1’deki tüm kuralları kontrol etmekteyiz.
CÜMLE SONU BULMA UYGULAMASI SONUÇLARI
CÜMLE SONU BULMA ÖRNEĞİ
Senin ne kadar kısa boyun varmış. Sabahları erken kalkman iyi olur. Onu hastanede ziyaret etmen çok iyi olur. Kazanmak için çok çalışmalı. Üniversiteyi kazanmak istiyorsan şimdiden çalışmalısın. Hiçbir zaman ışını zamanında yapmadın. Arkadaşına bu şekilde davranman hoş değil. Seneye memlekete gitmeyi düşünüyorum. Bu kitabı ileride daha da genişletmeyi düşünüyorum Diyelim ki kazandın. Tut ki Mars’ta yaşam var, bize bunun ne yararı olacak?
CÜMLE SONU BULMA FONKSİYONU ÇIKTI EKRANI
TÜRKÇE METİNLERDE KELİME YOĞUNLUK ANALİZİ BULMA UYGULAMASI
Derlem (bütünce, corpus (İng.))16 belli prensipler çerçevesinde özel veya genel amaçlı metin ya da konuşma parça ya da bütünlerinin, üzerinde yapılacak araştırmaya uygun işaretlemelerle beraber bir araya getirilmesinden oluşan bütündür. Günümüz derlemlerinin elektronik ortamda tutularak, erişim ve kullanım kolaylığı sağlanması yaygındır (Kennedy,1998). Bu da derlem oluşturma çabalarının bir akademik bilişim aktivitesi olarak ele alınmasını gerektirir.
Bir derlemden nasıl yararlanılabilineceğine kısaca değinmek bu emek yoğun sürecin değerlendirilmesinde yararlı olacaktır. Dilbilimin pek çok alt sahasında bir derlemden yararlanmak bilimsel bir metot olarak araştırmalara katkıda bulunmaktadır: bir sözlük oluşturulmasında günümüzün yeni sözcüklerinin nasıl bağlamlarda kullanıldığını araştırmak; söz dizimsel bir kuramın savlarını yaşayan dilin kesitlerinden örneklerle ve istatistiklerle desteklemek; bir dil öğrenimi sınıfında dilin yapılarına ve sözcüklerine örnekler vermek bu kullanımların sadece bazılarıdır (McEnery ve diğerleri, 1996). Doğal dil işleme alanında son yıllarda ağırlıklı olarak kullanılan istatistiki modellerin başarılı kullanımı için bol miktarda veriye, yani bir derleme ihtiyaç duyulur (Manning ve Schütze, 1999).
Uygulamamız sayesinde isteyenler derlem oluşturabilecekler. Kelime yoğunluk aracı ile uygulamamızda bulunan yazıları 4,3,2 ve 1 kelime tekrar ve “keyword density” denilen kelime yoğunluğu açısından ve toplam kelime adedini görüntüleyerek analiz edebilirsiniz.
KELİME YOĞUNLUĞU ANALİZİ ALGORİTMA ADIMLARI:
- Program içindeki metin giriş alanını kontrol et.
- Eğer metin alanı boş ise Fonksiyonu bitir
- Metnin tamamını küçük harfe döndür
- Metin alanındaki yazıyı boşluk, nokta, virgül, ünlem, soru işareti karakterlerine göre parçalara ayır.
- Tüm parçaları kelimeler isminde bir diziye ata.
- KelimeListesi isimli bir dizi oluştur
- Kelimeler dizisindeki eleman sayısınca döngü oluştur.
- Sıradaki kelimeler dizisi elemanını eleman isimli değişkene ata
- KelimeListesi Eleman İsimli değişkeni içeriyorsa kullanım sayısını 1 artır Adıma Git
- KelimeListesine Eleman değişkenini ekle
- KelimeListesi Dizisini Kullanım sayısına göre sırala
- Listeye Yazdır
- Bitir
KELİME YOĞUNLUĞU UYGULAMASI SONUÇLARI
KELİME YOĞUNLUĞU ÖRNEĞİ
Babam doğum günümü hiçbir zaman unutmaz.
Babam bakkala hep beni gönderiyor.
KELİME YOĞUNLUĞU FONKSİYONU ÇIKTI EKRANI
HARF YOĞUNLUĞU BULMA UYGULAMASI
DDİ’de derlemi oluşturup kullanan iki çeşit analiz bulunmaktadır; Biçimbilimsel ve istatistiksel Analiz17. Biçimbilimsel analiz, cümle sonu belirleme, kelime türlerini (isim, sıfat, vb.) belirleme ve kelimelerin parçalarını (kök, ek, vb.) analiz etme gibi kelimelerin biçimsel durumlarını inceler. İstatistiksel analiz iki türlü yapılabilir; harfler ve kelimeler üzerine. Sesli ve sessiz harflerin dizilimi, harflerin ngram analizleri, harfler arasındaki ilişkiler, vb. harfler üzerinde yapılabilen analizlerdir, buna “Harf Analizi” denir.
HARF ANALİZ ALGORİTMASI
- Giriş
- Metni Küçük Harfe Döndür
- Toplam Karakter Sayısını Toplam Değişkenine Ata
- Karakter sayısınca döngü oluştur
- Eğer karakter frekans dizisinde varsa 7. Adıma git
- Karakteri frekans isimli diziye ekle 8. Adıma Git
- Karakterin frekans değerini 1 artır
- Metnin sonu değilse 4. Adıma git
- Frekans isimli diziye sırala
- Frekans isimli diziyi yazdır.
HARF ANALİZİ UYGULAMASI SONUÇLARI
HARF ANALİZİ ÖRNEĞİ
Annem ikimiz arasında hiçbir ayrım yapmaz.
Şu adamlar tehlikeli görünüyor.
HARF ANALİZİ FONKSİYONU ÇIKTI EKRANI
GERÇEKLEŞME
Yukarıda adımları sıralanan algoritmalar kullanılarak geliştirilen projemizde kök ve ekleri bulmak için nZemberek18 isimli açık kaynak kodlu Doğal Dil İşleme Kütüphanesi
kullanılmıştır. .Net FrameWork 4.0 altyapısıyla Visual Studio 2010 Express Edition ile geliştirilen uygulama Visual C # ile kodlanmıştır.
NZemberek, Java ile geliştirilmiş Türkçe dilleri için NLP kütüphanesi olan açık kaynak kodlu Zemberek19 projesinin (https://github.com/ahmetaa/zemberek-nlp) .Net portudur.
Şu anda, Zemberek2 ile aynı işlevleri gerçekleştirebilmektedir. Nedir bu işlevler?
NZemberek ile:
- Denetleme
- Denetleme sonrası hatalı kelimeler için öneri oluşturma
- Çözümleme (morfolojik ayrıştırma)
- Sadece Ascii karakterleriyle yazılmış metni Türkçe karakterlere dönüştürme
- Türkçe karakterlere yazılmış metni sadece Ascii karakterleriyle yazılmış metne dönüştürme
- Heceleme yaptırabilirsiniz.
UYGULAMA ARAYÜZÜ VE MENÜLER

Dosya Menüsü
| a. | Dosya Aç | : Bilgisayar İçindeki herhangi bir metin belgesini |
| uygulama içerisinde görüntülemek için kullanılır. | ||
| b. | Klasör Aç | : Bilgisayar içerisindeki herhangi bir klasörün |
| içindeki tüm metin belgelerini birlikte açmak için kullanılır. | ||
| c. | Kaydet | : Uygulamanın metin alanı içerisinde yer alan |
| metinleri Metin dosyası biçiminde (.txt uzantılı) kaydetmek için kullanılır. | ||
| d. | Dışa Aktar | : Uygulama esnasında elde edilen sonuçları metin |
| dosyası biçiminde (.txt uzantılı) kaydetmek için kullanılır. | ||
| e. | Kapat | : Uygulamayı kapatmak için kullanılır. |
| 37 | ||
Düzen Menüsü
| a. | Kopyala | : Seçili Metni kopyalar |
| b. | Kes | : Seçili metni keser |
| c. | Yapıştır | : Hafızadaki metni yapıştırır |
| d. | Tümünü Seç | : Metnin tamamını seçer |
| e. | Temizle | : Metin alanına temizler |
| f. | Listeyi Temizle | : Çıktı ekranını temizler |
| g. | Renklendirmeyi Temizle | : Metin alanındaki biçimlendirmeleri temizler |
Türkçe Araçları
- Kelime İncele : Metin Alanı içinde seçili olan kelimenin Kök veEklerini gösterir
- Ulama Bul : Metin alanı içerisinde yer alan metin içindekiulamaları bulur
- Ünlü Daralması Bul :Metin alanı içerisinde yer alan metin içindeki ünlü daralması olaylarını bulur
- Ünsüz Sertleşmesi Bul :Metin alanı içerisinde yer alan metin içindeki Ünsüz Sertleşmesi olaylarını bulur
Analiz Araçları
- Cümle Bulma : Metin alanı içerisinde yer alan metnin cümlelerini bulur
- Kelime Kullanım Yoğunluğu: Metin alanı içerisinde yer alan metindeki kelimelerin kullanım sıklığını bulur.
- Harf Kullanım Raporu : Metin alanı içerisinde yer alan metindeki karakterlerin kullanım sıklığını bulur.
Yardım
| a. | Program Kullanımı | : Projenin kullanımı hakkında bilgi gösterir. |
| b. | Proje Raporu | : Proje raporunu gösterir |
| c. | Hakkında | : Projeyi geliştirenler hakkında bilgi verir. |
SONUÇLAR VE TARTIŞMA
Tüm Yapılan Çalışmalar İlgili elde edilen sonuçlar aşağıdaki gibi sıralanmıştır:
Ulama bulma fonksiyonumuz %100 çalışmaktadır. Türkçe bir metin içerisindeki tüm ulama olaylarını başarıyla bulup, metin içinde renklendirme yapabilmektedir. Çıktı ekranına ulama olan kelimeleri listeleyebilmekte ve istenirse çıktı ekranının kaydedilmesi başarıyla gerçekleşmektedir.
Ünlü daralması fonksiyonumuz Türkçe metinlerin içerisinde yer alan ünlü daralmalarını büyük bir başarıyla bulabilmektedir. Ancak bazı kelimelerin cümle içerinde niye kullanıldıklarını ve anlamları bilinmeden daralma olup olmadığını tespit etmek imkansızdır. Örneğin “diliyor” kelimesinde eğer dilmek manasında kullanılırsa ünlü daralması yok fakat dilemek manasında kullanıldığında ünlü daralması meydana gelir. Bu tarz kelimelerin ses olaylarını bulunamamıştır. Bu tarz istisnalar olabildiğinden bunları program kullanıcıları göz ardı etmemelidir.
Ünsüz sertleşmesi fonksiyonu ile Türkçe metinler içerisinde var olan ünsüz sertleşmesi olayları başarı ile bulunabilmektedir.
Ancak bazı yapım eki alan kelimeleri yeni bir kelime olarak algıladığından bunların içerisindeki ses olaylarını bulamamıştır. Kullandığımız NZemberek kütüphanesinin bazı yapım eki alan kelimelerin eklerini bulamamasından kaynaklanan bu duruma “atkı” kelimesi örnek verilebiliriz. “atkı” kelimesinde “–gı” yapım eki var olduğu halde kelimenin ek ve köklerini ayıramamıştır. Bu durumda bu kelimedeki ses olayının bulunamamasına yol açmıştır.
“Atkı” kelimesinin NZemberek tarafından bulunan olası çözümleri aşağıdaki gibidir.
KELİME İNCELEME RAPORU
—————————————————-
atkı kelimesi için olası çözümler
ÇÖZÜM :
KÖKÜ atkı Tipi: Tür İsmi
Ek 0 = ISIM_KOK
Cümle sonu bulma fonksiyonu tam bir başarı ile çalışmaktadır. Türkçe bir metin içerisinde, yazım kurallarına uygun yazılmış tüm cümleleri başarı ile ayırt edebilmektedir. Türk Dil Kurumunun yazıl ve dil bilgisi kuralları çerçevesinde Türkçe cümle sonu belirten noktalama işaretlerini tespit edebilmektedir. Yine cümle içerisindeki sayı, tarih gibi normalde cümle sonu olmadığı halde kullanılan işaretleri de anlayıp cümleyi bitirmemektedir. Cümle içerisinde kısaltmaları tespit ederek kısaltmaların sonundaki noktalama işaretlerini de cümle sonu olarak görmemektedir. Cümle içindeki tırnak işaretleriyle yazılı alt cümleleri de cümleden ayırmadan sadece ana cümleyi ayırt edebilmektedir.
Tüm bunların yanında projemiz metinlerin yazım denetimini yapabilmektedir.
Kelimelerin kök ve eklerini bulabilmektedir.
Metin içindeki kelime kullanım sıklıklarını hesaplayabilir ve kelimeleri kullanım sıklıklarına göre sıralayabilir.
Benzer olarak metin içinde kullanılan karakterleri kullanım sıklığına göre sıralayabilir ve kullanılan karakterlerin kullanım sayıları ve oranlarıyla birlikte gösterebilir.
Projemiz Türkçe dilbilgisi yardımcısı olarak başarıyla kullanılabileceği gibi geliştirdiğimiz özgün, kaliteli ve hızlı fonksiyonlar ile yapılabilecek Doğal Dil Çalışmaları için temel oluşturmaktadır.
KAYNAKLAR
- http://tr.wikipedia.org/wiki/Do%C4%9Fal_dil_i%C5%9Fleme (15.01.2014)
- Aktaş, Ö. (2006). Türkçe için Verimli bir Cümle Sonu Belirleme Yöntemi. Paper presented in Akademik Bilişim
- 2006/Bilgi Teknolojileri Kongresi IV, Pamukkale University, Denizli.
- Nadas, A. (1984). Estimation of probabilities in the language model of the IBM speech recognition system. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32:4, sayfa 859-861
- Kukich K. (1992). Technique for automatically correcting words in text. Periodical Issue Article of ACM Press, sayfa 77-439
- Church, K. & Gale, W. (1991). Probability Scoring for Spelling Correction. Statistics and Computing, sayfa 93-103.
- Jurafsky, D. ve Martin, J.H. (2000). Speech and Language Processing, Prentice Hall, sayfa 193-199.
- Güngördü Z. (1993). A lexical-functional grammar for Turkish. Yüksek Lisans Tezi. Bilgisayar Mühendisligi Bölümü , Bilkent Üniversitesi,
- Shannon, C.E. (1951). Prediction and Entropy of Printed English. The Bell System Technical Journal, 30:1, sayfa 50-
- Crystal,D. (1991). A Dictionary of Linguistics and Phonetics, Blackwell,üçüncü basım.
- Sinclair,J. (1991). Corpus Concordance, Collocation. OUP http://www.akademik.adu.edu.tr/myo/didim/webfolders/File/agirlama%20programi/td101/TD%201 0%20%20Sunusu_dosyalar/frame.htm (15.01.2014)
- http://www.edebiyol.com/ulama.html (15.01.2014)
- http://tr.wikipedia.org/wiki/%C3%9Cns%C3%BCz_benze%C5%9Fmesi (15.01.2014)
- http://www.tdk.gov.tr/index.php?option=com_content&id=187 (15.01.2014)
- Oflozer, K, ve Say, B. Ve Özge, U. (2001). Bilgisayar Ortamında Bir Derlem Geliştirme Çalışması Orta Doğu Teknik Üniversitesi
- Shannon, C.E. (1951). Prediction and Entropy of Printed English. The Bell System Technical Journal, 30:1, sayfa 50-
- https://code.google.com/p/nzemberek/ (15.01.2014)
- https://github.com/ahmetaa/zemberek-nlp (15.01.2014)
Bu projeyi yaparken kullandığımız uygulamaları ayrı ayrı anlattığımız yazılarımıza sitemizin Doğal Dil İşleme örneklerini paylaştığımız yazılarımızda, diğer TUBİTAK Örnek projelerine de sitemizin Tubitak projeleri bölümlerinden ulaşabilirsiniz.
Projemiz hakkındaki yorumlarınızı bekliyoruz